Insights on the power of distributed ML development
Executive Summary
Distributed Machine Learning (ML) development is based on collaborative and structured development activities across different stakeholders.
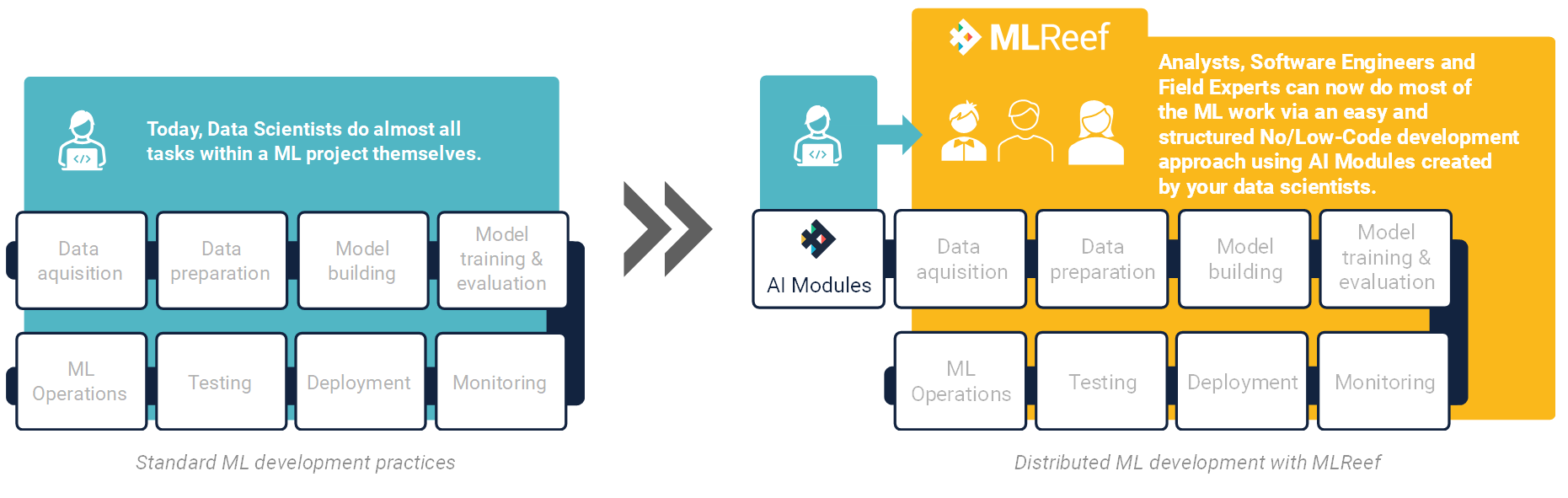
This development method stands in contrast to regular, centralized ML development practices where data scientists cover major parts of the ML life cycle themselves.
There are major gains of Distributed ML Development practices, such as:
- higher ML throughput: Distributing ML activities on different actors, not just data scientists (DS) allow organizations to develop more ML projects at the same time.
- less dependency on AI talent capacity: Distributed workflows embed different actors in the ML value chain. Consequently, the knowledge is spread across the organization as well as easing the burden on the data scientists.
- data preparation with experts: Domain experts are ideally suited to reduced complexities and increase quality during data acquisition, data handling and data processing activities.
- higher model acceptance: Increased participation during the development results in higher acceptance and ownership of the deployed models and its predictions.
MLReef is the first platform that introduces distributed Machine Learning development. They key mechanic is a hybrid between pro-code - for data scientists´ operational freedom - and no/low code - for accessibility for laymen.
In the next chapters, we will discuss and give you a preview of central elements, workflows and explicit use cases of distributed ML development.
Central elements of distributed ML development
The technical core elements of distributed ML development principles are based on the capacity of covering major parts of the ML life cycle, reproducibility and concurrency for data handling, code elements and pipelines. On top of these, workflow and accessibility mechanics need to support collaboration, flexibility and ease of use. All these elements are necessary to distribute the work across different actors within the organization, independent from their role and expertise.
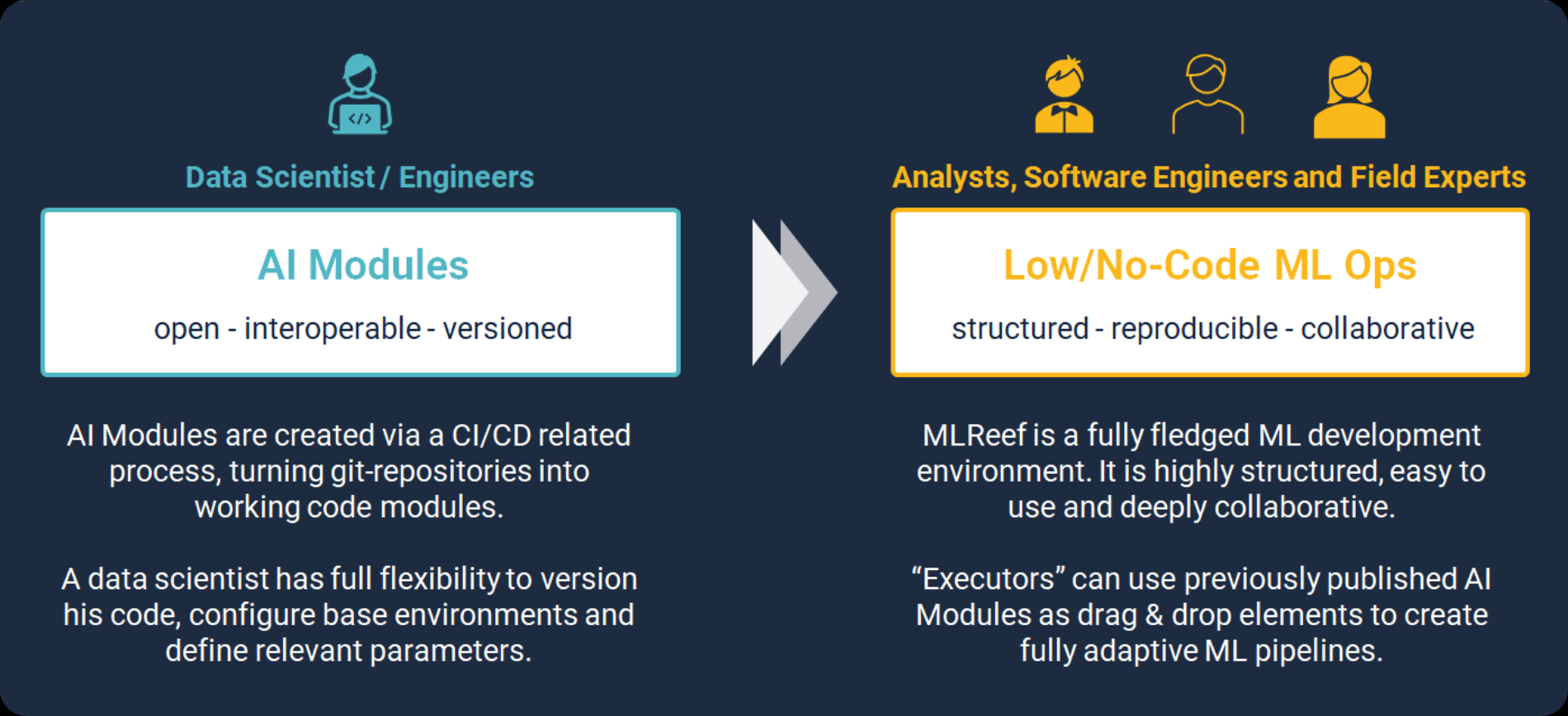
In software engineering, where distributed development fundamentally originates by toolkits such as (git and git based Source Code Management (SCM) platforms. In contrast to this, data science needs several more layers and some fundamentally different workflow mechanics. In addition to SCM capacities, for versioning and working concurrently on code, DS platforms need to support easy pipeline creation from data handling, model training & evaluation as well as flexible deployment mechanism.
We believe that distributed ML development needs to address the needs of DS as well as to other stakeholders equally. In our view, modular approach that enables DS to write any code function without limitations as well as a simplistic explorability, re-usability and adaptability of these code modules within pipelines for other participating stakeholders, is needed. The operational mechanics needed therefore spawns from full flexibility to widespread simplicity.
Distributed ML workflows
In terms of internal workflows involving several, ground different stakeholders require structure on one side and transparency on the other. Collaboration is central and communication vital for the success. In MLReef we solved this by modular and reusable git-based elements — we call them AI Modules. These are the central working sphere for data scientists.
Much of the other activities within the ML life cycle can (and should) be handled by domain experts, analysts, product owners and other stakeholders that are able to understand much better the final requirements of a deployed model. The most widespread ML development approach binds these stakeholders only peripherally into the value chain. This is especially tricky in many cases when data complexity is high and requirements for the predictive accuracy business sensitive.
In MLReef, other stakeholders, especially those at the departments and teams where the final model is aimed to be deployed at, are a very central role in the development process. Foremost, in the development of the data sets (from acquisition to pre-processing and analysis). An essential aspect is iteration in data sets with full version control and replicability capacities. If teams can easily iterate and validate the performance of a model, not only in terms of internal architecture, hyperparameters and other pipeline variables but also with variations of data sets, the final performance of the model can only be improved.
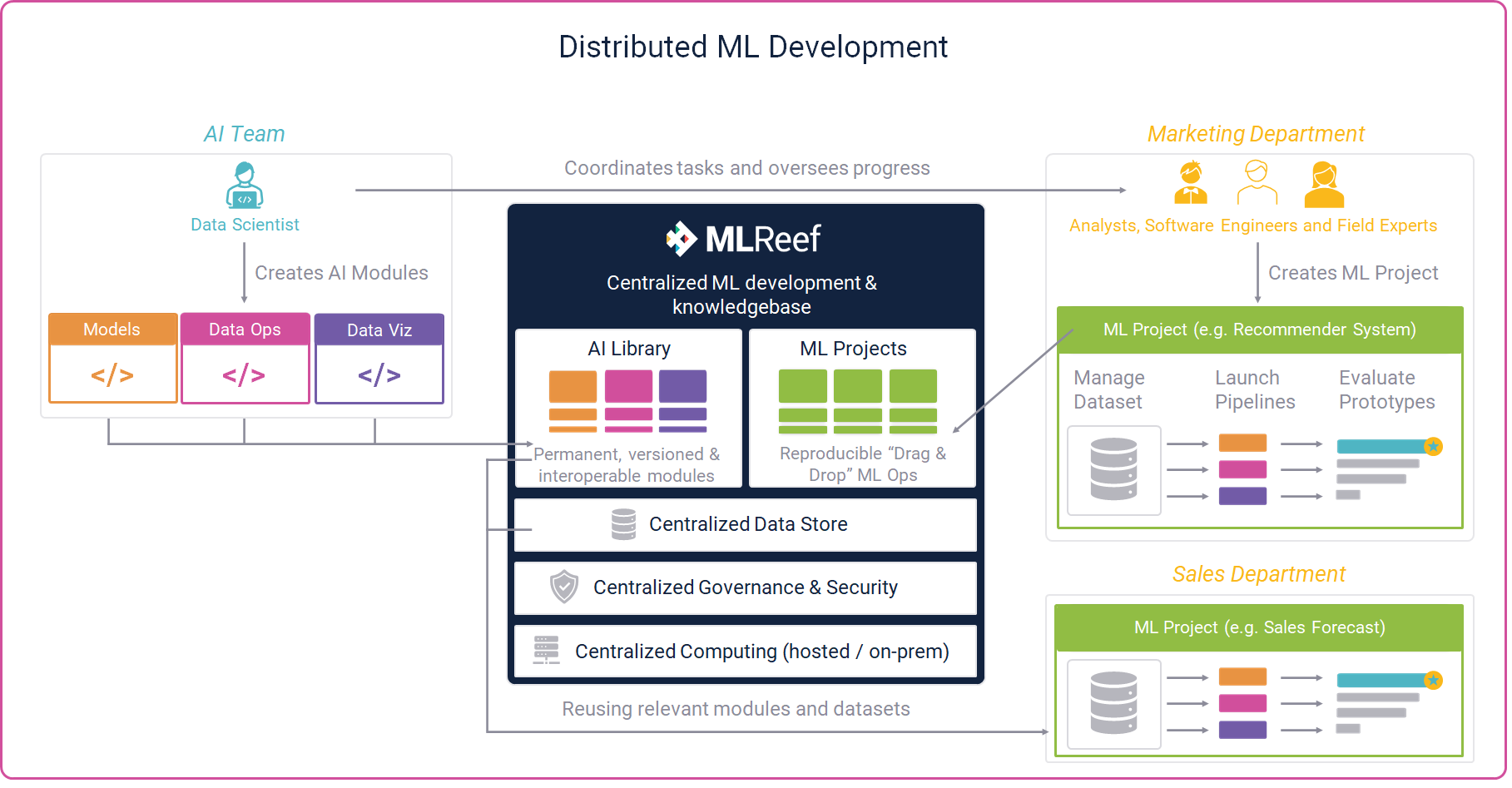
The acceptance of a model is key to maintain expected ROI. The benefits of including domain experts early in the development phase are high, in terms of quality, maintenance activities, improvements and acceptance of predictions.
A glance to first adopters - use case presentation
Distributed ML development is an entirely new mechanism in conventional data science. During the last year, we could validate the model with different use cases and organizations.
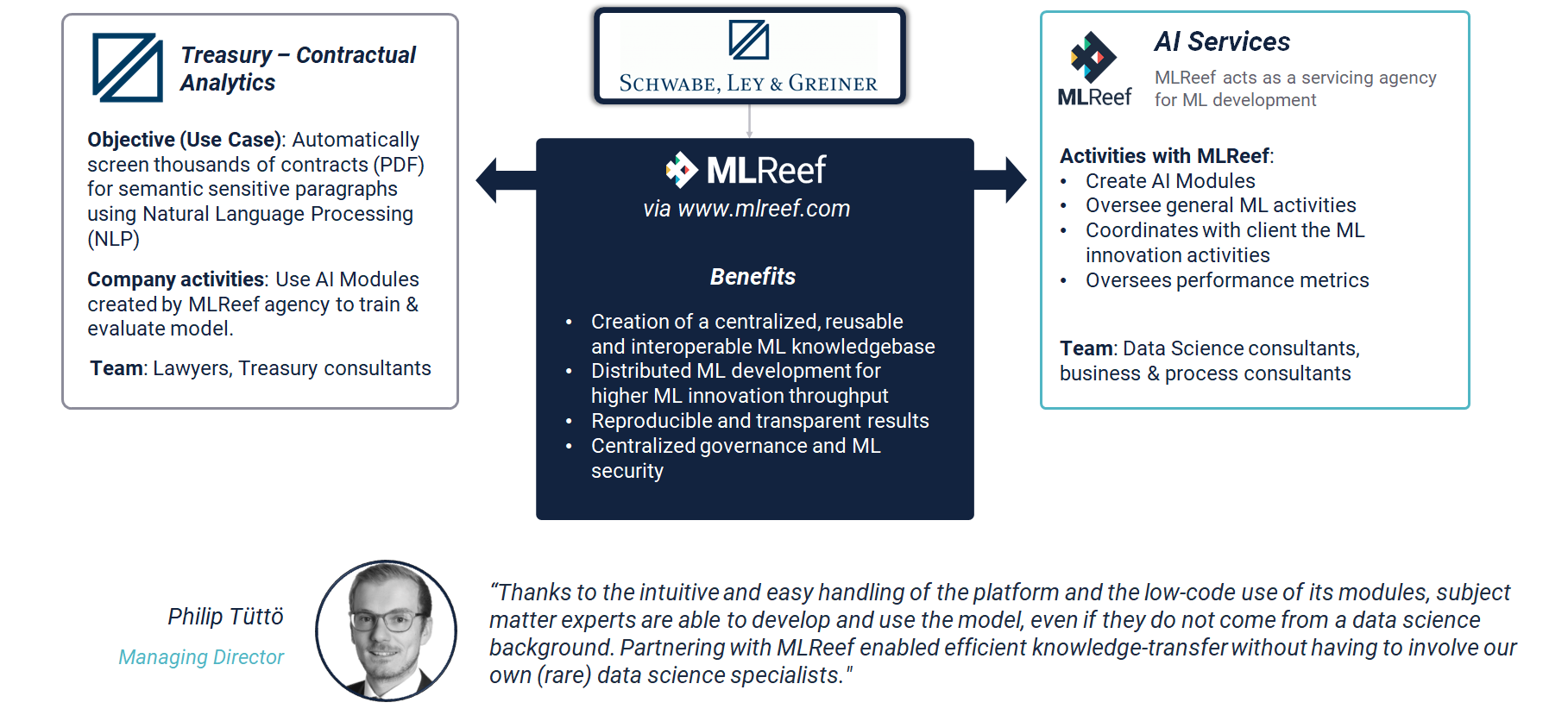
With Schwabe Ley & Greiner (SLG) - a leading European Treasury Consulting firm – we found an ideal partner to premiere MLReef´s distributed workflow mechanics into a real world use case and organization. SLG’s subject matter experts partnered with MLReef’s data scientists in the development process. The outcome, in terms of operational effectiveness, can be summarized as follows:
From MLReef side (we acted as developing agency):
- between 2 - 5 hours per week to develop the NLP model as AI Module
- initially, we had to write several rules to read with high accuracy the texts within a PDF. Due to high variance in their structure, several hours were spent on this task
- Continuous consultations and guiding during the ML development phase
From SLG´s perspective:
- Their treasury and legal experts where in charge of creating the data sets
- They operated AI Modules, that we as agency published for them, as drag and drop elements
- SLG managed the entire project and autonomously launched pipelines to train models.
- Legal experts and treasury consultants validated the model performance and reported back to us for feedback and improvements.
In total, around 80% of the development effort came from subject matter experts within SLG. Around 20% were contributed from data scientists from MLReef. The general quality of the model was impressive and can now be further trained and developed by SLG.