Global MLOps and ML tools landscape

Executive Summary
The term MLOps is – for anyone in the Artificial Intelligence field – the one magic word to solve them all. It combines all Machine Learning relevant tasks, from managing, processing, and visualizing data, running and tracking experiments to putting the creating models into production, ideally at scale, compliantly and securely. It defines the process of operationalizing ML activities to create AI based applications and services.
At MLReef we operate in this market, but we had only a rough idea what other tools, platforms and services there are. To find out, we conducted a global search for relevant providers, finding more than 300 in total! We decided to clean what we found to active projects and list only those specifically pointing to Machine Learning tasks and objectives.
The results is the first version of our global MLOps platforms and ML tools landscape.
Please reach out to us for feedback, corrections or additions at: hello@mlreef.com
Key statistics
- More than 300 platforms and tools where analysed, where around 220 were active projects
- In Europe, only 4 MLOps platforms could be identified (MLReef, Hopsworks, Valohai & Polyaxon).
- Most platforms and tools cover between 2 - 3 ML tasks (focused approach)
The MLOps life cycle
The first view was to see what tools and platforms are offering services for individual taks and processes within the ML life cycle. To keep a better overview, we split the life cycle in major 4 ML areas:
Data Management: All ML focused tasks to explore, manage and create data(sets).
Modelling: All pipeline related tasks from data processing to trained model validation.
Continuous Deployment: All tasks related to the "Ops" part of MLOps - launching, monitoring and securing productive models.
Computing & Resources: All activities and functions related to computing and resource management.
Note: One provider can be found in several ML tasks. We identified their offerings as best we could by screening their websites, demo videos and hands-on testing.
MLOps platform comparison
We wanted to go deeper and analyzing tools, that position themselfs as holistic platforms covering a broader spectrum of ML tasks. This differentiation needed to be conducted based on identifiable and specific metrics, so to try to avoid arbitrary selection. In our view, an MLOps platform needed to:
- at least cover 5 tasks from the ML life cycle,
- be at least present at 2 main areas (e.f. data management + modelling),
- position itself as MLOps platform.
Based on this criteria, out of the +220 identified platforms and tools only 18 were MLOps platforms.
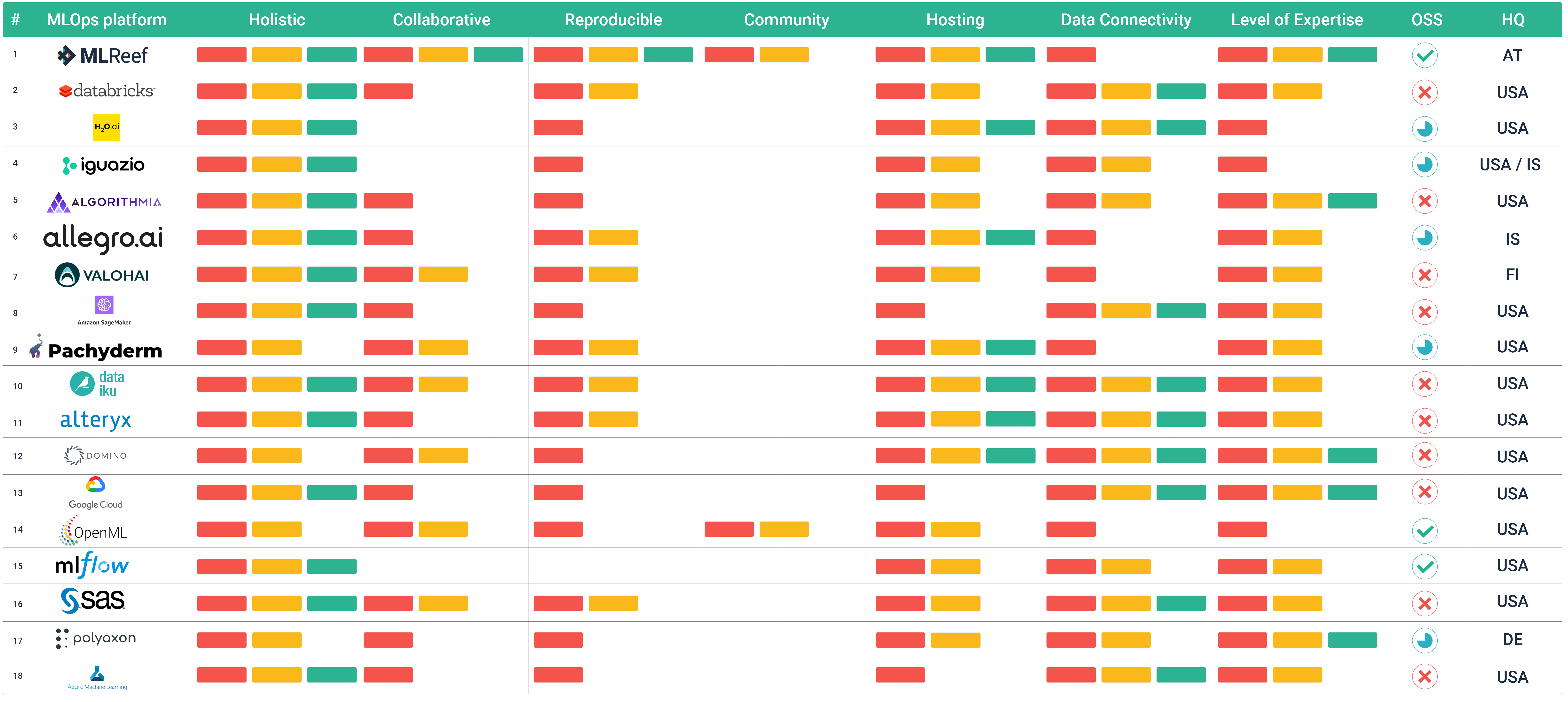
Review characteristics
The next intreguing question was: what separates these platforms from one another?
We decided that a good approach would be not to list specific features and functions, but rather more generic perspectives on their offering. We propose the following "soft" criteria which, in our view, define a great MLOps platform:
Holistic: An MLOps platform needs to cover a broad selection of ML tasks. The rule for bar received are: one for covering one main area, two for covering two, and three for covering three main areas.
Collaborative: A key task in MLOps is collaboration and is increasingly important as ML solutions are becoming more embedded in organizations. We define collaboration based on the possibility to share and work concurrently on pipeline on data processing, modelling and managing runtime environments. The rules: one bar for covering 1 out of the three.
Reproducible: Reproducing the entire value added chain in ML is very important, as it allows to understand predictions and increases confidence in the deployed model. We defined reproducibility as tracking and versioning of data, source code & hyperparameters and environment configuration. The rule: one bar for each of variable topic (e.g. data, code & hyperparameters, runtime environment).
Community: We see access to community content as increasingly relevant, as more and more datasets, code based functions and libraries are available. GitHub has been a good source for code, so does Kaggle and other code / project hosting platforms. Nevertheless, we would like to see a direct use of community synergies in a MLOps platform. The rule: one bar for each sharable ML element within the MLOps platform (outside of the team!).
Hosting: Where can one use the platform? Cloud only, self-hosted or only locally. The rule: one bar for each of the main three possibilities.
Data connectivity: This section describes the data aquiring possibilities within the platforms. We identified four: on-platform, via data sources (data connectors), direct APIs to third party applications and via direct access to data bases. The rule: one bar for each of the before mentioned data connectivity types (limited to 3 bars).
Level of expertise: We see it as increasingly important to have easy of use in general operability of a platform, as more newcomers enter the ML market. This last characteristic is more difficult to assess as it relates to many different aspects (UI/UX, workflow mechanics, help documents, general concepts, etc). This part is more open for discussion, but we tried to be as objective as possible. The rule: one bar for expert only, two bars for experts and advanced users and three bars for experts, advanced and beginners.
In-depth review (MLOps platforms)
The following section will have a closer look at the MLOps platforms listed above. In a following landscape analysis, we also will include sections for every tool and platform we found (but this was a bit too much for now!).
MLReef

Description: MLReef is an open source MLOps platform that provides hosting to Machine Learning project. It is build on reusable ML modules made by your team or the community to improve fast iteration and easy adoption. It is based on git to foster concurrent workflows and more efficient, collaborative and reproducible ML development.
Open source repo: https://gitlab.com/mlreef/mlreef or https://github.com/MLReef/mlreef


Databricks

Description: One open, simple platform to store and manage all of your data and support all of your analytics and AI use cases.
Open source repo: https://github.com/databricks


H2O

Description: H2O.ai is the creator of H2O the leading open source machine learning and artificial intelligence platform trusted by data scientists across 14K enterprises globally. Our vision is to democratize intelligence for everyone with our award winning “AI to do AI” data science platform, Driverless AI.
Open source repo: https://github.com/h2oai


Iguazio
Description: The Iguazio Data Science Platform transforms AI projects into real-world business outcomes. Accelerate and scale development, deployment and management of your AI applications with MLOps and end-to-end automation of machine learning pipelines.
Open source repo: https://github.com/iguazio/


Hopsworks

Description: Hopsworks 2.0 is an open-source platform for the development and operation of ML models, available as an on-premises platform (open-source or Enterprise version) and as a managed platform on AWS and Azure.
Open source repo: https://github.com/logicalclocks/hopsworks


Algorithmia

Description: Algorithmia is machine learning operations (MLOps) software that manages all stages of the ML lifecycle within existing operational processes. Put models into production quickly, securely, and cost-effectively.
Open source repo: https://github.com/algorithmiaio


Allegro AI

Description: End-to-end enterprise-grade platform for data scientists, data engineers, DevOps and managers to manage the entire machine learning & deep learning product life-cycle.
Open source repo: https://github.com/allegroai


Valohai
Description: Train, Evaluate, Deploy, Repeat. Valohai is the only MLOps platform that automates everything from data extraction to model deployment.
Open source repo: https://github.com/valohai


Amazon SageMaker

Description: Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML.
Open source repo: https://github.com/aws/amazon-sagemaker-examples


Pachyderm

Description: Hosted and managed Pachyderm for those who want everything Pachyderm has to offer, without the hassle of managing infrastructure yourself. With Hub, you can version data, deploy end-to-end pipelines, and more. All with little to no setup, and it’s free!
Open source repo: https://github.com/pachyderm/pachyderm


Dataiku

Description: Dataiku is the platform democratizing access to data and enabling enterprises to build their own path to AI in a human-centric way. Note: They are limited to tabular data only.
Open source repo: hhttps://github.com/dataiku


Alteryx

Description: From Data to Discoveries to Decisions — In Minutes. Analytics that automate and optimize business outcomes.
Open source repo: https://github.com/alteryx


Domino Data Lab

Description: Let your data science team use the tools they love. And bring them together in an enterprise-strength platform, that enables them to spend more time solving critical business problems.
Open source repo: https://github.com/dominodatalab


Google Cloud Platform

Description: Avoid vendor lock-in and speed up development with Google Cloud´s commitment to open source, multicloud, and hybrid cloud. Enable smarter decision making across your organization.
Open source repo: https://github.com/GoogleCloudPlatform/


OpenML

Description: As machine learning is enhancing our ability to understand nature and build a better future, it is crucial that we make it transparent and easily accessible to everyone in research, education and industry. The Open Machine Learning project is an inclusive movement to build an open, organized, online ecosystem for machine learning.
Open source repo: https://github.com/openml


MLflow

Description: MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud).
Open source repo: https://github.com/mlflow


SAS

Description: Solve the most complex analytical problems with a single, integrated, collaborative solution – now with its own automated modeling API.
Open source repo: https://github.com/sassoftware


Polyaxon

Description: Reproduce, automate, and scale your data science workflows with production-grade MLOps tools.
Open source repo: https://github.com/polyaxon


Microsoft Azure

Description: Limitless data and analytics capabilities. Yes, limitless. Get unmatched time to insight, scale, and price-performance on the cloud built for data and analytics.
Open source repo: https://github.com/Azure


All tools and platforms listed
Below we list all researched tools and platforms we found during our research.
Data Management
This main area within the ML life cycle focuses on managing the data. We decided to have it as a separate area as there are many aspects to it that lie outside of the "Modelling" area.
Data exploration and management
Tools and platforms that help you manage, explore, store and organize your data.
Data labeling
Tools that will support your effort in labeling your data to create training datasets.
Amazon Sage Maker - Data Labeling
Data streaming
Data streaming services and tools for loading large amounts of data directly into data pipelines.
Microsoft Azure Stream Analytics
Data version control
Tools and platforms offering version control for data. This is specially relevant, as data is an integral part in a models performace. Reviewing data changes and data governance are essential for full reproducibility.
Data privacy
Data privacy contains anonymization, encryption, highly secure data storage and other mechanism to leave data private.
Data quality checks
Mechanisms to ensure healthy data.
Modelling
This main area within the ML life cycle focuses on creating ML models. This includes all steps directly connected with creating models, such as preparing data, feature engineering, experiment tracking up to model management. One could say, this phase is where all the magic happens.
Notebook / ML code management
Tools and platforms that help you manage, explore, store and organize your notebooks or your ML operations. We explicitly did not include SCM platforms, such as GitHub or Gitlab, as they are not specifically focused on ML (although being perfectly capable of hosting these functions).
Data processing and visualization
Dedicated data processing (e.g. data cleaning, formatting, pre processing, etc.) and visualization pipelines, which target at analyzing large amounts of data. We explicitly excluded simple data representations, for example to show data distribution in tabular data (there are plenty tools that do this).
Feature engineering
Dedicated feature engineering and feature storing platforms and tools.
Model Training
These tools and platforms have dedicated pipeline and functions to train Machine Learning models.
Experiment tracking
Tools and platforms that offer ways to track, compare and record metrics from model training.
Model / Hyperparameter optimization
Tools and platforms that allow you to searching for the ideal configuration of hyperparameter for your model (e.g. including bayesian or grid search, performance optimizations, etc.)
Auto ML
Automated machine learning, also referred to as automated ML or AutoML, is the process of automating the ideal model configuration based on the architecture, data and hyperparameters. AutoML is a more advanced method of model optimization, but is not always applicable.
Model management
Model management encompasses model storage, artifact management and model versioning.
Model evaluation
This taks involves measuring the predictive performance of a model. It also includes measuring the computing resources needed, latency checks and vulnarability.
Model explainability
Removing the black-box syndrom of (especially) deep learning models by analyzing its achitecture, weights distribution paired with test data, heatmaps, etc. These tools offer dedicated features for model explainability.
Continuous Deployment
This main area within the ML life cycle focuses on putting a trained model into production.
Data flow management
These tools let you manage and automate data flow processes during inference (what happens with new data that comes in?), measure performance and security issues.
Feature transformation
Similar to the process during model training but now during inference tasks. As new data flies in, it needs to be transformed to fit the input data the model has been trained at. These tools allow you to create feature transformations applied to productive models.
Monitoring
Model performance monitoring is extremly important, as deviations in data distribution or computing performance might have direct implications on business logics and processes.
Model compliance and audit
This tasks involves giving transparency on model provenance.
Model deployment and serving
Tools and platforms that integrate model deployment capabilities.
Model validation
Model validation
Adapting a model to be compatible with other frameworks, libraries or languages.
Computing management
This main area within the ML life cycle encompasses managing the computing infrastructure. This is especially relevant, as ML sometimes requires big amounts of storage and computing resources.
Computing and data infrastructure (servers)
These organizations provider the required horsepower for your ML projects (in terms of hardware).
Environment management
Custom scripts require packages, libraries and a runtime environment. The following tools and platforms will help you to management your base environments.
Resource allocation
The following tools and platforms support managing different resources (such as computing instances, storage volumens, etc.). Also, some include budgeting and team prioretizations for controlling spending.
Scaling
These tools offer elastic scaling of deployed model and computing tasks.
Security & privacy
These tools will let you manage privacy topics (such as GDPR compliance) and increase your security standards when deploying your models into production.